
This is a talk about how to create better design and code, using Pelikan cache as a case study.

A little background about myself: I've been working at Twitter since Nov 2010, a really long time by Silicon Valley standards these days. All this time I've been working on cache, which allows me to touch pretty much every aspect of it – server, client, cluster management; and I've done pretty much every job possible – SRE, developer, architect, capacity planner, and manager.

As anybody working on something long-term can attest, quality and joy matters in the long term, even just providing the same functionality.
Take GPS for example – it's a modern technology that allows us to navigate with ease. However, it is only possible after we have incredibly accurate clocks (e.g. atomic clocks). Measuring time is something that's conceptually simple, and has been done for centuries. However, without improving the precision of such simple tasks, amazing modern technology like the GPS cannot happen.

This is why I believe in the power of quality. I also believe in the power of storytelling. There are plenty of theories and principles on better design and code, but how do we apply them, what do they look like in real life?
These can be best communicated via concrete examples, i.e. stories.

First, let me present you the "case" in our case study.

Pelikan started from our desire to unify all the cache solutions used at Twitter. We've been using open-source software and their forks for years, including Memcached/Twemcache, Redis, and later developed other software such as Fatcache, Slimcache and Twemproxy.
On the one hand, we recognize the great structural similarity in these services; on the other hand, we hesitate to introduce some of them and other new features into production, as we hesitate to support a plurality of codebases. We realize to make real progress, we have to consolidate and improve existing solutions, so we can avoid the maintenance baggage moving forward.

Next, let's look at the actual process of improving what we have.

The very first question before trying to make something better is: "is it worthwhile?"

Well, I have bad news for you – often enough, the answer is No. There are plenty of cases where "good" is good enough.
People do not take their fanciest china to a picnic. Most scenarios do not warrant "better". Instead, before we try to make things better, "good" has to happen first. History does not wait for the perfect person or occasion to be created.

Timing is important. For example, Twitter infrastructure in general went through stages: first we used available tech that worked, then went on to patch and fork, eventually we had enough experiences and resources to reconsider our problems and solutions from first principles. We could not have made the kind of improvements that are happening now 5 years ago.
One tool that has been repeatedly used to assess projects is the 2x2 risk matrix by Ryan King (an ex-Tweep): it compares the status quo and the goal of a project. Generally, we want gradual improvement, and avoid aiming for perfection when having nothing. The motto is "evolution, not revolution".

Achieving "better" requires careful evalution. Is our effort better spent on creating “something new”, or “something better”? If we think it is more beneficial to improve something that already exists, do we understand concretely the weakness and strength of existing solutions, and therefore what will make it stronger? Do we know the technical solution that addresses those weaknesses? How much resources would it take to implement?
These questions need to be repeatedly asked, until we are honestly confident about our answers. For Pelikan, the amount of time since its inception and the amount of political capital it cost showed how difficult it can be to justify betterment.

So now the project is on. How do we make sure the execution meets the goals?
I would argue that skillfulness alone does not guarantee better solution. Often, one also needs to have a better understanding of the problem. Insight and skills are the two necessary ingredents to achieve better design and code.

How to get insight? We ask questions.
In 1950s, there was a popular show called The $64,000 Question. Good questions are incredibly valuable. What's more, they stand the test of time much better than answers. Today, we often use a slightly different version of the phrase, "the million dollar question". So the value of a good question not only tracks inflation in the US since the 50s – which is about 10x – it even beats it.

For Pelikan, we set out to ask a set of questions related to cache. These are good questions coming out of our years of operations and working closely with our customers (which register at more than 100 internally). There is only one problem: these questions are impossible to answer.
Take the first question for example: caching is so ubiquitous – it is used for CPU, in CDNs and just about every other system, how can we characterize caching for our project?

As it turns out, constraints are our friend. We cannot build a cache for everybody and everything, but we can build a good cache for something.

Look at the four images on this page. All of them can be described by one word – a farm. But look how vastly different they are depending on their context!
By having a narrow(er), well-defined context, it is much easier to understand and clarify design goals and limitations. This leads to more robust system that is less likely to be misused. Making fundamental assumptions explicit also reminds us to re-assess when the underlying context changes over time.

So we rewrote the questions for the specific context that we care about, which made them a lot easier to answer.
By looking closely at the underlying infrastructure and our use cases, we were able to clear some myth previously held as truth: for example, while it is often advantageous to host data purely in memory, under certain circumstances it's perfectly fine to use non-volatile storage for caching.

We summarize our insight into the problem as a concrete goal: when we say we want to build a better cache, we mean we want build a production-ready cache, which provides predictable runtime performance, is operations friendly, and is maintainable in the long term.

These areas get further expanded according to the way cache is used in our context, providing specific criteria that can be evaluated against.

Next up, we adopted a set of principles to keep execution on track.

Interface or indirection is probably the most important concept in building systems. David Wheeler has the saying, "Any problem in computer science can be solved with another layer of indirection".
We inevitably create interfaces while building software – unless your entire service is a single giant function, you are creating interfaces whether trying or not. So really the emphasis here is on “well-groomed”.
In practice, the only way to achieve this is to make defining interfaces an explicit exercise, and revise them along the way.
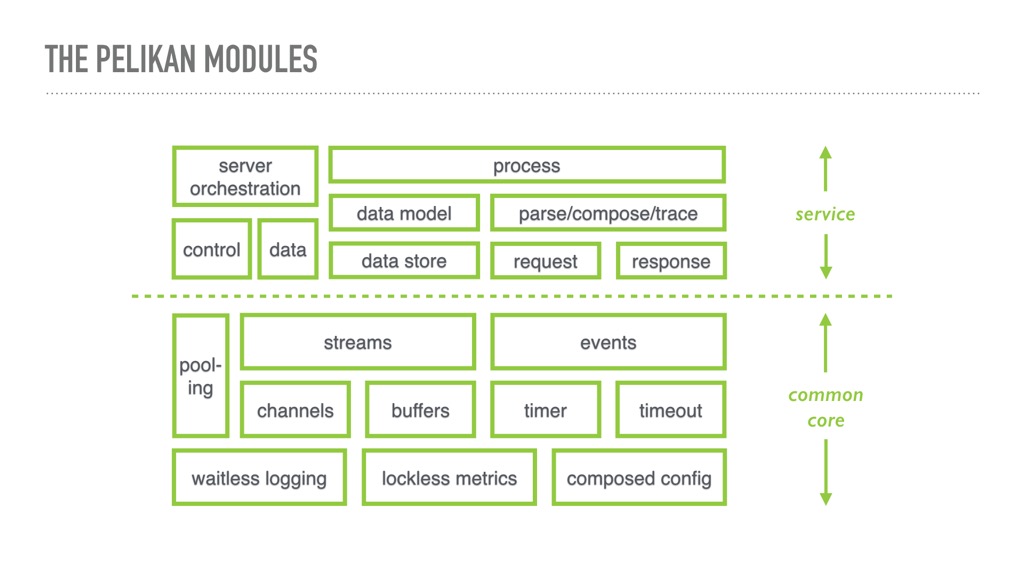
The modules of Pelikan were created before implementation started, and modified many times as we flesh out implementation. It was certainly helpful in identifying the parts, and reasoning about the relationships between them.
The details of this diagram do not matter. You may have a completely different chart for your system, but the same practice applies.

A concept closely related to interface is abstraction. When do we need it? How can we avoid over- or under- applying abstraction?
In the 90s, the Olson twins starred in a show called Two Of A Kind, that succinctly describes the principle of abstraction – create an abstraction if and only if there are at least two different things of the same kind. Don't bother when there is only one. On the other hand, if there are two, chances are one can come up with a more or less proper abstraction by looking at these instances at the same time.
Pelikan is filled with such examples: protocol abstraction is created by looking at Ping, Memcached and Redis protocols. Channel is defined by summarizing TCP/UDP connections, Unix Domain Socket, and pipes. Some of them are not yet implemented, but we put them through the thought process to make sure the abstraction covers them.

There is often a tension between building a small set of features quickly, and implementing them in a way that doesn't require rewrite in the future. How can we know we are on the right track without implementing everything upfront?
The aforementioned thought exercise with potential features is helpful for building a maintainable framework. Often times, just think about how something new could be implemented given the existing abstractions and interfaces is enough to prevent us from making decisions that will certainly make things hard or impossible down the road. Minimizing such decisions yields a more maintainable code base.

Layering is one of the most powerful concept leading to the explosion of software. We all stand on the shoulders of giants. But sometimes, that shoulder patch can be a little slippery. A Lego tower like this is not possible if all the pieces have smooth surfaces. Writing good software is similar – we want different layers to have good grip between them, not simply piling bricks on top of one other.
Abstraction is here to help break down complex problems / systems, not to calcify the modules. Making a change at one level often means making changes at other levels as well. For example, when writing Pelikan server we noticed the same sequence of buffer-related functions being called repleatedly, therefore we added a new function to the buffer interface to simplify such cases. In another case, we realized using the previous timer interface makes object life-cycle management difficult for one-off timers, and decided to change the corresponding timing wheel interface.

"God is in the detail", and the only way to get a glimpse of God is through rigor. Just like system security depends on the weakest link, achieving design goals hinges on the part that is least carefully implemented.
For example, with Twemcache, we had to disable logging beyond the ERROR level in production, because it directly calls `write()` which occasional requires flushing to disk. Rarely but eventually, such activity slows down the main thread when another unrelated background task creates contention at the disk, which is beyond our control. Logging is something developers rarely give a second thought about, and yet to achieve deterministic runtime, we had to completely change how logging is implemented in Pelikan. We made similar effort for metrics recording and the use of `malloc()` as well.

Rigor also means spending a lot of time thinking about corner cases. A lot of states in distributed systems are hard to produce with simple unit test. In practice, people often resort to using “battle-tested” systems whose states are more thoroughly explored, even just by chance. If one wants to build a more robust solution from the beginning, they have to carefully reason about the problem in an exhausitve way – Margaret Hamilton did not have the chance to "battle-test" her team's software for Project Apollo, instead, they foresaw what might go wrong.
On top of that, it would be great if formal proof is more widely used to verify the correctness of a system. Developers should make debugging info a first-class citizen, because things inevitable go wrong.

Details also means paying attention to seemingly frivolous things, such as names. You'd be surprised by the amount of time we spent arguing about names. But after being in meetings where people try to correct each other every five minutes because they had slightly different interpretation of the same name, I would like to argue that agreeing on definition is much more than just bike-shedding, but the cornerstone of collaboration.

How do we get a sense that what we are creating is indeed better? Use style as a guide for assessment.
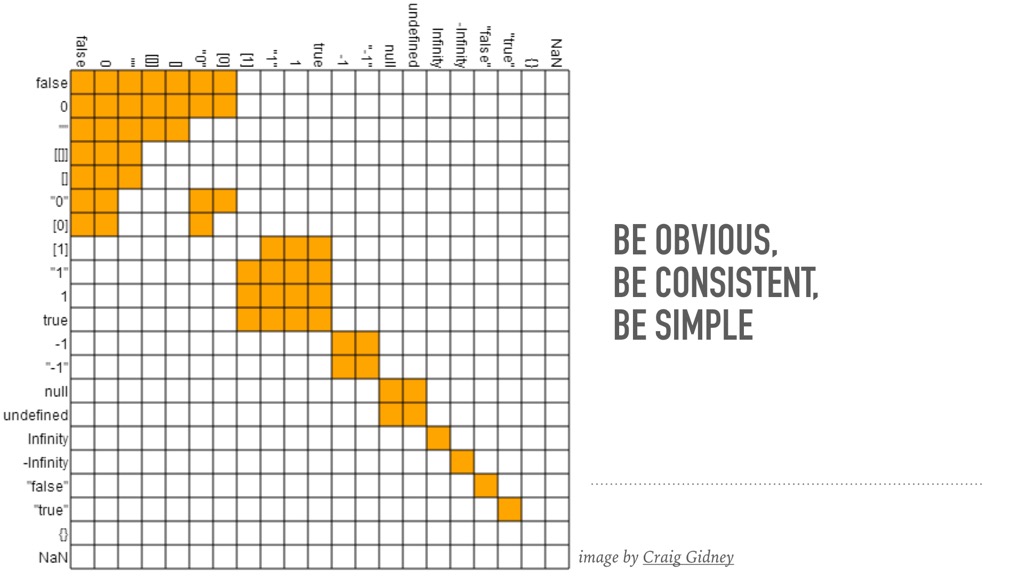
Good style should be obvious, consistent, and simple. It is hard to notice that when things are done right, just like one would not pay attention to the ground underneath unless there is a bump that trips us. Instead, it is much easier to give examples when things are not quite right.
Here is the truth table of Javascript's equal operator (`==`). As you can tell almost immediately, it is not that straightforward, in fact, it is quite "interesting". This is the opposite of what we want.

Some would say, "sure, poking fun at Javascript, that's too easy" – fair point. Let's look at some code in Pelikan.
On the right column is the entire setup of all modules used by Pelikan's Twemcache server in `main()`. It is fairly plain and uninteresting. On the left was the same code several commits ago. As you can see, it is far less regular, a lot more interesting, and it goes on...

... and on ...

... and on.
It should be obvious that the code on the right is much better – it is boring, and can be easily overlooked.

Another powerful style element is the presence of universal rules. An ornate room like this has lots of details. However, it does not appear to be chaotic, in fact, it is quite beautiful. Why? Because there is a lot of symmetry and repeated patterns throughout.
The same should be true for code. Good code exhibits symmetry and repeated patterns when such concepts apply.

The two blocks of code on this page are for setting up module configuration and metrics, respectively. Despite providing different functionalities, they have similar shapes and patterns. A closer examination reveal the reason behind it – at a meta level, configuration is how a service builder gives input to various modules, while metrics are how a service builder gathers output about the internal states of the same modules. The symmetry in form reflects the deeper symmetry in their purposes. Code like this can be called beautiful, for it surfaces the underlying truth.

We start our betterment effort with great insight and past experiences, and produced something "better". As we carry the project forward with with new features and functionalities, how can we prevent quality degradation?

One answer is never to underestimate the power of prototypes. We were able to do better, because we learned from previous experiences. To continue to produce better design and code, we need to gain similar experiences even with new features.
I worked on Twemcache for 2 years without understanding how event loops worked . When working on Pelikan, I had to learn about epoll and kqeuue from scratch, making many mistakes in the process. Later on, in a separate project, I proposed how to abstract event handling with a set of interfaces, and got increasingly frustrated when nobody in the room seemed to know what I was talking about after hours of meetings. Then I realized that nobody else in the room had implemented event loops before, just like how I started. So I suggested everybody go home and write a throw-away prototype echo server, just to get some intuitive understanding of the details. The group reconvenened the following week, and amazingly, the discussion flowed smoothly, and we were able to reach an agreement and moved on with the design.
The same practice should be used whenever working on something new, even within an established codebase. First make it work, and learn from that process. Only then we can make sure the final version is better.

A common myth in software development is insisting reusing existing code. If I can get a dollar for everytime someone asks me why I don't just use X/Y/Z, I'd be eating at some very fancy restaurant tonight.
Granted, there's nothing wrong with using existing code. The problem is code reuse is not a binary decision, it is a continuum. It goes anywhere from just borrowing the idea, to wholesale adoption. It is the developer's job to decide where on the spectrum their project falls.
Code reuse is often "awkward" because existing code can be "slightly off" in terms of functionality and (more likely) style. In practice, what we did with Pelikan is to broadly survey related projects, shamelessly copy and paste code that fits into our design, and relentlessly edit them afterwards. We started out with about 50 percent old code from existing implementations, but over time have made changes to them as if they were our own. As a result, the project feels consistent, and we were able to avoid writing brand-new logic especially for the high-risk portion of the design.

If we want a project to stay "better", we need to remember that nothing is sacred. Everything is subject to rewrite if we find a better way to do it.
In the past few years I’ve never met a feature that took more than a day to implement, and that is entirely deliberate. Once I realized a feature would take longer than a day, I started asking if it is due to some design misfit or architectural shortcoming. And often enough, it is. So a new feature becomes refactoring – the interface may need modification, or the modules need to be restructured, or an abstraction requires re-visiting. After spending days doing that and changing 1000+ lines of code, at the end I could add the feature with just a small amount of additional effort.
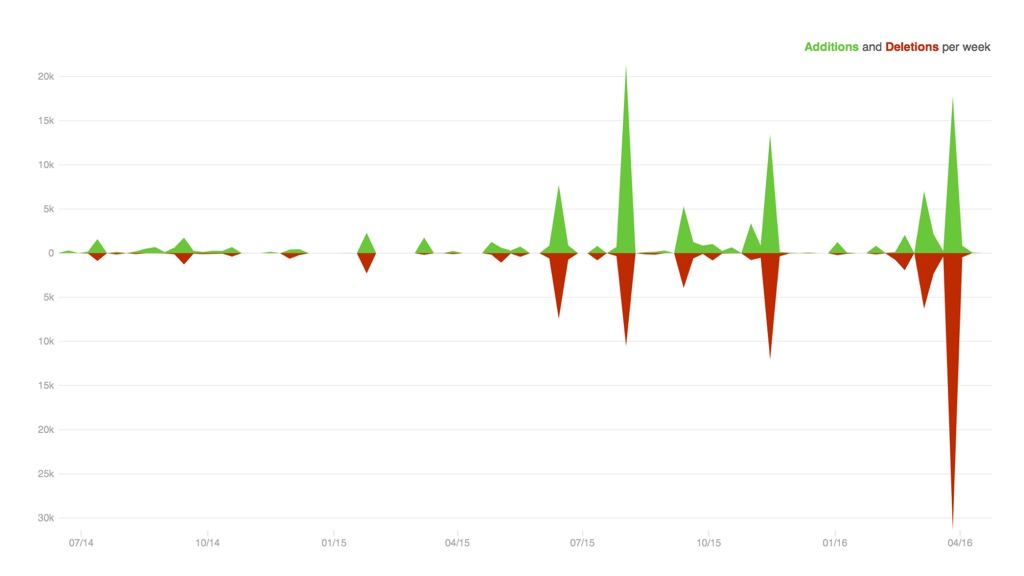
Here's what a code base with frequent refactoring looks like – there isn't a linear accumulation of new code. Instead, development is mostly around updating existing code, reflected in almost as much deletion as there is addition in git history.

We also need to be mentally prepared when working on projects aiming at betterment. Unless you projvide the only solution in the space, I suspect almost everyone is susceptible to doubting the value of their projects.
Some amount of doubt is perfectly normal. Competition motivates us to do better. But one needs to handle it with a healthy dose of awareness: knowing where things overlap, knowing one's strength and weaknesses, and be ready to adapt to challenges coming in every possible direction.

In the end, there really is no guarantee that any single project we build will “take off”. And this includes Pelikan. So why are we still doing this? Why putting so much effort into trying to make something better?
Because practice is the only way to gain true mastery. That experience transcends any single project, and will benefit every subsequent endeavor. Anything that could be said and learned in a talk like this pales in the face of a conscious decision of improving one's craft through exercise.
Projects come and go, but craftsmanship is forever.

The End